Stop Rereading Your Documents. Let the AI Study Them Once.
How Zenii implements Karpathy's compiled knowledge pattern as a local HTTP API — so every tool in your stack shares one knowledge base.
You read a research paper. Three weeks later, a question comes up. You can't remember the answer. You search your notes, find nothing useful, and paste the PDF into your AI assistant again. Same cost, same latency, and depending on the day, a slightly different answer.
This is the trap in naive RAG workflows: the system retrieves raw context, then re-synthesizes the answer on every query. For dynamic document stores, that's the right call. But for knowledge that doesn't change (research papers, architecture decisions, API conventions, meeting outcomes) you're paying the synthesis cost over and over for no reason.
Andrej Karpathy proposed a better pattern llm-wiki.md: compile the knowledge at ingest time. The LLM reads a document once, writes structured wiki pages, and future queries draw on pre-built knowledge. No regeneration. No inconsistency.
The catch: you have to build it yourself.
Zenii ships that pattern out of the box: ingest once, compile durable wiki pages, then query them from any tool through a local HTTP API.
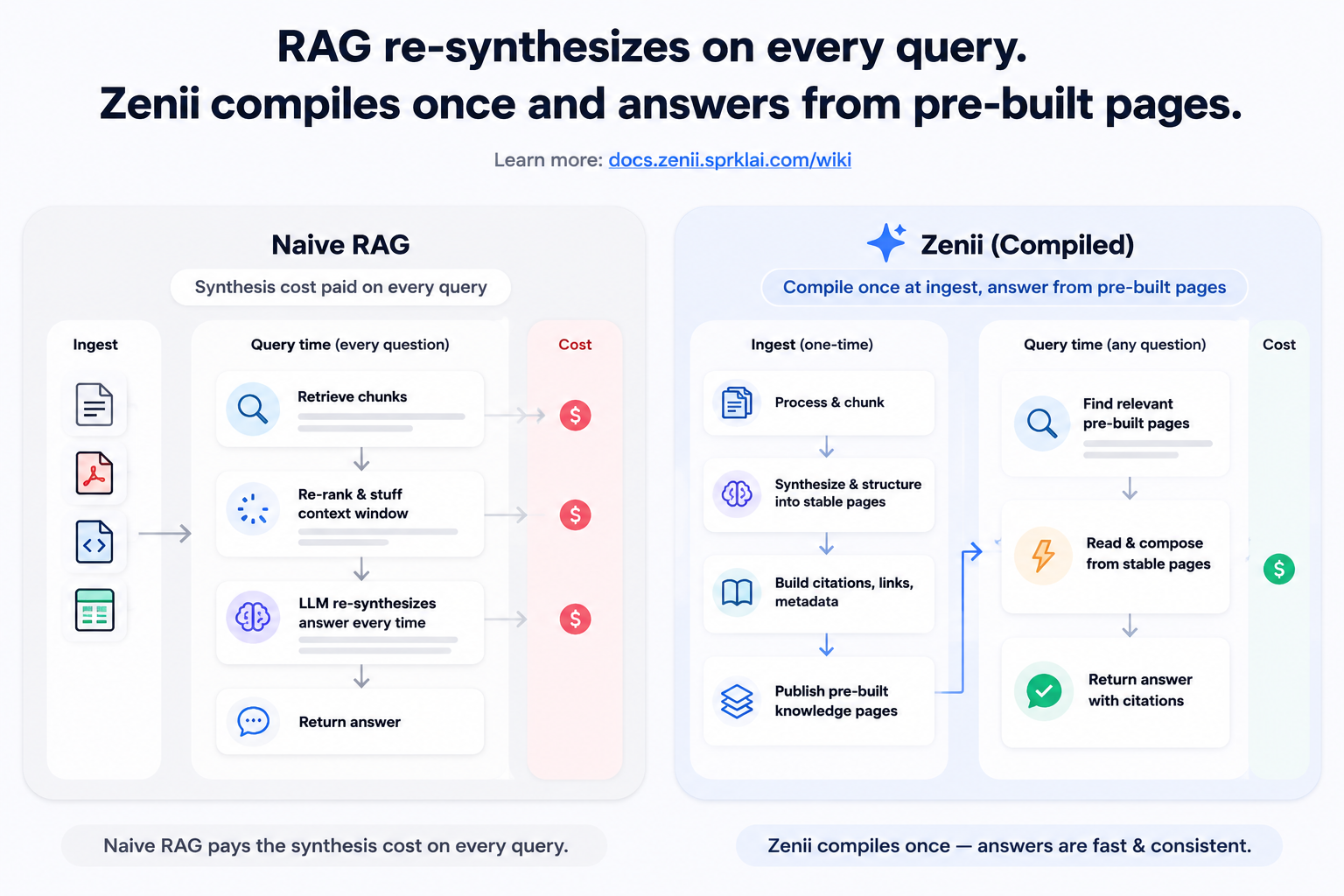 Left: naive RAG pays synthesis cost on every query. Right: Zenii compiles at ingest — later answers read from stable pre-built pages.
Left: naive RAG pays synthesis cost on every query. Right: Zenii compiles at ingest — later answers read from stable pre-built pages.
What Zenii is
Zenii is a local-first AI assistant platform built in Rust. Its Desktop, CLI, TUI, and Daemon clients share one core library and talk to the same local HTTP + WebSocket gateway at 127.0.0.1:18981.
The wiki is the relevant part: a compiled knowledge layer every client and every external tool can query.
How the wiki works
When you ingest a document, the LLM runs a two-pass synthesis:
- Entity pass: every named person, organization, tool, model, and dataset gets its own page. The rule is explicit: err on the side of more entity pages.
- Concept synthesis: reusable ideas, comparisons, domain topics, and saved query answers are extracted and cross-linked.
Geometric Memory - The Secret to Implicit Reasoning and the Future of LLM Design.md — concepts, entities, and topics appearing on knowledge graph.
The output is 5–15 structured pages written under a typed taxonomy:
wiki/pages/
concepts/ # techniques, patterns, abstract ideas
entities/ # people, orgs, tools, models, datasets
topics/ # domains that organize related pages
comparisons/ # side-by-side analyses
queries/ # saved answers to important questions
Every page uses a strict schema: YAML frontmatter and a markdown body with [[wiki-links]] for cross-references:
---
title: "Mixture of Experts"
type: concept
tags: [llm, architecture, efficiency]
related: ["sparse-activation", "switch-transformer"]
confidence: high
sources: [scaling-survey.pdf]
updated: 2026-05-05
---
## TLDR
Mixture of Experts routes each token to a subset of specialized subnetworks,
enabling models to scale parameters without proportionally scaling compute.
Underlies GPT-4, Mixtral, and other frontier models.
The LLM instructions that drive ingestion live in wiki/INGEST_PROMPT.md, a plain markdown file you can edit to tune how knowledge is compiled for your domain, without touching any code.
 The structured output: typed taxonomy on the left, a rendered concept page on the right.
The structured output: typed taxonomy on the left, a rendered concept page on the right.
It's a local knowledge API
The wiki isn't a tab in a desktop app. It's an HTTP service. Any tool in your environment can call it.
# Ask from the CLI
zenii wiki query "What naming conventions do we follow for REST routes?"
# Ingest any document
zenii wiki ingest architecture-decision.pdf
# Call it from any language
curl -X POST http://localhost:18981/wiki/query \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{"question": "What naming conventions do we follow for REST routes?"}'
The response comes back structured, not a re-synthesized paragraph, but a direct answer grounded in what the wiki knows:
{
"answer": "Use plural nouns for collection routes and kebab-case for path segments.",
"citations": ["api-conventions.md", "rest-routing.md"],
"saved_page": null
}
import requests
from pathlib import Path
BASE = "http://localhost:18981"
HEADERS = {
"Authorization": "Bearer <your-token>",
"Content-Type": "application/json",
}
# --- Query the wiki ---
def query(question: str) -> dict:
r = requests.post(f"{BASE}/wiki/query", headers=HEADERS, json={"question": question})
r.raise_for_status()
return r.json()
# --- Ingest a file from disk ---
def ingest_file(path: str) -> dict:
with open(path, "rb") as f:
r = requests.post(
f"{BASE}/wiki/ingest",
headers={"Authorization": HEADERS["Authorization"]},
files={"file": (path, f)},
)
r.raise_for_status()
return r.json()
# --- Ingest raw text (e.g. standup notes, changelogs) ---
def ingest_text(content: str, filename: str) -> dict:
r = requests.post(
f"{BASE}/wiki/ingest",
headers=HEADERS,
json={"content": content, "filename": filename},
)
r.raise_for_status()
return r.json()
if __name__ == "__main__":
# Ingest a document once — the LLM compiles it into wiki pages
ingest_file("architecture-decision.md")
# Query it any number of times — no re-synthesis, same answer every time
result = query("What naming conventions do we follow for REST routes?")
print(result["answer"]) # "Use plural nouns for collection routes…"
print(result["citations"]) # ["api-conventions.md", "rest-routing.md"]
# Batch-ingest a directory of standup notes
for note in Path("standups/").glob("*.md"):
ingest_text(note.read_text(), note.name)
print(f"Ingested {note.name}")
Every Zenii client (Desktop, CLI, TUI) reads from the same wiki. Via MCP, external AI agents like Claude Code or Cursor can call wiki routes as tools mid-conversation: query for conventions before suggesting a refactor, ingest a PR description before reviewing it.
Any automation platform that makes HTTP calls (n8n, Zapier, Make) can pipe documents straight into your wiki automatically.
| Tool | What it gains |
|---|---|
| Cursor / Copilot | Query your conventions before suggesting code |
| Claude Code | Check architecture decisions before refactoring |
| n8n / Zapier | Auto-ingest meeting notes, changelogs, emails |
| Python scripts | Query the wiki programmatically in any workflow |
| Any LLM agent | Call /wiki/query as a tool — no RAG infra to build |
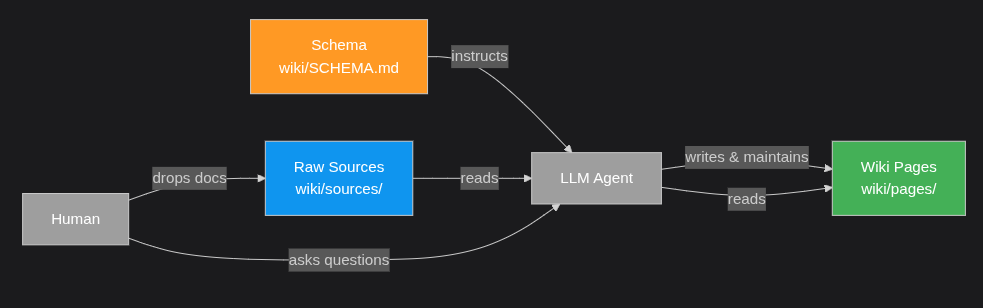 One wiki. Every tool shares it. Cursor knows your conventions. Zapier ingests your meetings. Your agent recalls it all.
One wiki. Every tool shares it. Cursor knows your conventions. Zapier ingests your meetings. Your agent recalls it all.
The desktop: knowledge as a graph
The Zenii desktop app renders your wiki as a visual knowledge graph. Concepts, entities, topics, and queries are nodes; the [[wiki-links]] between them are edges. Everything you've read, in one navigable view.
The rest of the system
Multi-format ingestion: PDFs, DOCX, PPTX, XLSX, images, and EPUBs are converted to markdown via the MarkItDown CLI before the LLM sees them. Originals stay untouched; re-ingestion always converts from the original binary, not a prior conversion.
Lint: zenii wiki lint finds broken wikilinks, orphan pages, missing metadata, and stale entries. --fix patches what it can automatically.
Memory sync: zenii wiki sync pushes page TLDRs into Zenii's hybrid memory (FTS5 + sqlite-vec). The agent recalls wiki knowledge across sessions without you having to ask.
Audit trail: content hashes, source-to-page mappings, and an append-only run log in .meta/. Re-ingestion is reproducible, and you can regenerate everything after editing your ingest prompt.
When not to use this
This is not a replacement for RAG over fast-changing data. If your corpus changes hourly (customer support tickets, live docs, recent news), retrieval still makes sense. The compiled wiki is for knowledge you want to stabilize: decisions, research, conventions, and long-lived project context.
Why compile instead of retrieve
Once ingested, answering a question reads only the relevant pages. No re-synthesis, no extra token cost, same answer every time. Knowledge improves incrementally: new sources add pages, lint keeps links clean, and regenerate lets you recompile everything as your prompt evolves.
Karpathy described the pattern. Zenii ships it as local infrastructure: one binary, one port, one knowledge base every tool in your environment can read from.
Zenii is in active development. Star it on GitHub or try the wiki API locally.